How to tell if your tables need a REORG? A case study using REORGCHK (Db2 LUW)
When I started my first job as a DBA, I was shown the crontab of one of the database servers I was supposed to manage. I remember noticing that there was a script that had the word “reorg“ in its name. It was executed once a week. This script ran REORGs on all tables.
That day I didn’t know that reorganising tables on a timely basis just as creating backups is not a perfect strategy. Still better than no REORGs at all, but far worse than reorganising only those tables that currently require a REORG. But how do we know that a REORG is needed? And why do we need to reorganise the tables at all?
Reasons to REORG
Basically, there are 4 motives to reorganise a table:
- the table contains many empty pages,
- or lots of partially empty pages,
- there are many overflow records,
- you want to change the order of records.
Partially empty pages issue
After you delete a record, it’s just marked as removed in the slot directory, but physically, it’s still there. It’s called a “pseudo-deletion“ or “logical deletion“. If you want to free the space the removed record occupies, you need to reorganise the table. Otherwise, you’re left with unused space inside a page.
Empty pages issue
After you delete a bunch of subsequent records, you may end up with few completely empty pages. These pages are not automatically released, they’re still part of the table, they still contain the same data — they’re just marked as not used. Again, the “pseudo-deletion“. To free the space they occupy, you need to reorganise the table.
Overflow records issue
After you add a column to the table, or increase the size of a column (e.g. varchar(8) to varchar(16)), the table’s records become bigger and they don’t fit in their space anymore. It means the new/enlarged column must be stored in another page, leaving a pointer in its previous place. It leads to worse I/O (Db2 needs to read 2+ pages to read 1 record), which means slower read. To remove overflow records, you need to reorganise the table.
Order of records issue
When you add records to the table, they’re added at the end of the table (in the last page). However, you may prefer to order them differently, according to the index you usually use for SELECTs. To reorder your records, you need to reorganise the table.
To sum up, I described 4 different issues that may waste your disk space or degrade the performance, namely:
- unused space in data pages,
- unused data pages,
- overflow records,
- unwanted order of records.
How do I know that I have such problems?
If I see that my table grows slowly and I/O is not very bad, does it mean that I don’t experience any of these issues? Or, if I did some deletes or I altered a column, does it mean I necessarily have to reorganise the table? And if so, what kind of REORG is exactly needed? Maybe I should do full REORG every week during low traffic on the database?
Well…, REORG is not a backup that you should make in a timely manner. What you should do in a timely manner in case of table organisation, is checking if any REORG is needed and which one exactly.
There are different ways to do the check. I use two of them:
- if I want to use the output in my script, I go the developer way and build a SQL statement using SYSCAT.TABLES view and SESSION.TB_STATS table,
- if I want to just display the check results on the screen or save it in a file for later analysis, I use the REORGCHK command
REORGCHK

As you can see, the REORGCHK syntax is simple. You can just type “REORGCHK on table <tableName>“. But let’s analyse this diagram. First, I want to focus on the left half of this diagram. You have 2 options:
- “update statistics“
- and “current statistics“
If you choose the first option, RUNSTATS will be performed. So, in practice, there will be 2 commands executed sequencially: RUNSTATS and REORGCHK. This is the default option. In the Db2 documentation, everything what’s at the top, is the default option. And this is what you usually want. However, there are many DBAs, who run RUNSTATS before REORGCHK explicitly. In such case You should remember to specify “current statistics“ keyword to avoid waiting for Db2 until it collects all the statistics that you already have. Remember that RUNSTATS takes time, while REORGCHK is quick. Another reason you may want to use “current statistics“ option is when you’re sure that the table didn’t change much since last time the statistics had been collected.
OK, let’s move to the right half. It’s regarding the table or tables you want to reorganise. As you see, the default is “on table user“, which means all tables owned by the current user (“run time authorization ID”). I’ve never used it, but it’s good to know what’s the default. At the bottom you can see two other options:
- schema — it means you reorganise all tables from the given schema,
- and table.
The table option gives you the following opportunities:
- reorganise user tables,
- reorganise system tables,
- reorganise all tables,
- and reorganise a single table.
I usually send the output to a file. Thanks to that I have a file regarding a specific database or a single schema (if the database is too big) that I can easily analyse. When I run REORGCHK for the entire database, the command looks like this:
db2 “REORGCHK update statistics on table all“ > dbName_reorgchk.out
As you see, I add the keyword “update statistics“ explicitly. Technically, it doesn’t change anything (it’s the default option), but I think it’s good to use these keywords for 2 reasons:
- firstly, defaults change over time (e.g. logs in the backup: in the past “exclude logs“ was the default, now “include logs“ is the default),
- secondly, when someone else reads my command and doesn’t know what’s the default option for the command is, the explicit, verbose version will help.
OK, so what’s the output of the command? The output is divided into 2 sections:
- one regarding tables,
- and one regarding indexes.
Since this post is about tables only, I am going to skip the indexes part.
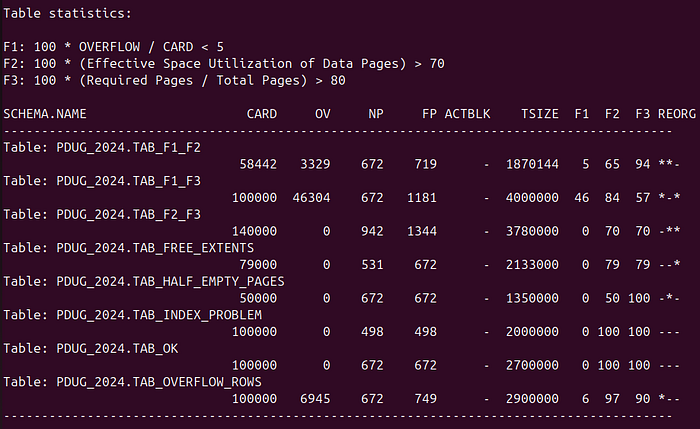
On the screenshot above, there is a part of a sample REORGCHK output (namely: “Table statistics” section) that I am going to analyse. It has a form of a table. Rows represent tables or table partitions. Columns show some statistics. The last column (REORG) is a REORG advisor — telling if you should (not) reorganise the given table (or partition).
About columns, one by one, starting from the left:
- CARD stands for cardinality, which is basically the number of records in the table,
- OV means overflow records — it tells us how many of the records are overflow,
- NP is the number of pages that contain data, it means all pages except for empty pages,
- FP is the total number of pages including the empty ones,
- ACTBLK is related only to MDC and ITC tables (it’s the number of active blocks) — we don’t need it today,
- TSIZE represents table size in bytes, but it’s only an approximation.
Then, there are mysterious F1, F2 and F3 columns (letter “F” stands for “function“). These are the most important ones — they store results of the following functions:
- namely F1 equals OV divided by CARD as a percentage — in human words it is the number of overflow rows divided by the total number of rows. In other words: percentage of overflow records in the table,
- F2 calculations are not clear (IBM didn’t share this information), however it indicates the percentage of space used to store the data versus the total allocated space for the given table,
- F3 equals NP divided by FP in percents, which is the percentage of pages containing some data comparing to the total number of pages.
There is also the last column called REORG. It tells you which function (F1, F2 or F3) returned a value suggesting that a REORG is needed. For example, if there are more that 5% overflow records, you’ll see an asterisk on position #1. If there are more than 20% empty pages, then you’ll see an asterisk on position #3. We’ll deal with it when we get to specific examples.
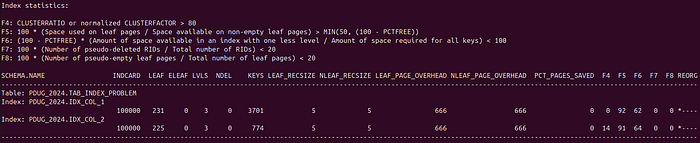
In the REORGCHK output, there is also information related to indexes (screenshot above). Of course assuming that you have any indexes. Therefore there are 8 functions in total (F1-F8), not only 3. I won’t cover index REORG today, but function #4 is important also for table REORGs that have an index or indexes. Namely F4 tells us how well the table is organised from the perspective of a particular index. In other words, this formula indicates the percentage of the table that is stored in the same order as the given index. When F4 is marked in the REORG column in the REORGCHK output, it does NOT mean you should definitely do the table REORG. I will explain it in a post about reorganising tables (coming soon, link will be here).
OK, let’s see how it works in practice. I created a schema PDUG_2024 with a bunch of tables (output repasted above). These tables are quite similar. I just made them look bad. As you see, there is TAB_OK, which is perfectly organised. TAB_INDEX_PROBLEM will be discussed later. The rest of the tables have some issues. There are 3 tables with overflow rows (OV column). In one of them, TAB_F1_F3, almost every second record is overflow. This table is generally the worst here. There are also many tables with many unused pages. Unused pages is the difference between FP and NP. If you divide NP by FP, you get the percentage of used pages. This value is represented by F3. For example table TAB_FREE_EXTENTS has 21% of unused pages, because its F3 is 79. Its F2 is equal to F3, which means that the pages that are in use, are very well clustered. At the opposite extreme there is TAB_HALF_EMPTY_PAGES table. Its NP equals FP, which means F3 is 100%, but F2 is 50. It means that all pages are in use, but they are half empty, as the table name suggests.
Now, let’s focus on the REORG column. As you can see, almost each possible value occurs in the picture. The thresholds for F1, F2 and F3 are: 5%, 80% and 70%. In my opinion it’s better to look at the functions, not asterisks, because they tell you more (range 0–100 instead of yes/no). For example both 2 top tables: TAB_F1_F2 and TAB_F1_F3 have asterisks on the first position, which means: REORG suggested due to overflow rows. But in one case the number of overflows is 5%, while in the other it’s 46%. So, while in one case this is a delicate suggestion, in the second case it is a loud scream.
As I promised, let’s discuss the TAB_INDEX_PROBLEM table. In the “Table statistics” everything seems perfect. However in the “Index statistics” we see that function F4 is marked in the REORG column (screenshot repasted above). F4 tells us how many records in the table are stored according to the given index. In case of index on COL_1 function F4 is 0. In case of index on COL_2 the value of F4 is slightly better, but still bad. You’ll see what we can do about this and previous issues it in the post regarding REORG TABLE (coming soon).
In addition to the REORGCHK command, there are more ways to check your tables for possible reorganisation needs. I am going to describe them on this blog later this year. Though REORGCHK is not very flexible and gives you limited information, it is the fastest and the most easy-to-use tool to check reorganisation needs. In my opinion it is sufficient in most cases.
